

深入探索全球效能最強且彈性的數據中心
現代數據中心的 AI 和 HPC 核心
通過 AI 和 HPC 解決全球最重要的科學、工業和商業挑戰。将複雜内容可視化,打造尖端産品,講述身臨其境的故事,并重塑未來城市。從大量數據集中提取新的見解。NVIDIA Ampere 架構專爲彈性計算時代設計,能夠應對多種挑戰,并在各種規模下實現出色的加速。
突破性創新
NVIDIA Ampere 架構以 540 億個晶體管打造,是有史以來最大的 7 納米 (nm) 芯片,包含六項關鍵的突破性創新。
第三代 Tensor 核心
NVIDIA Tensor 核心技術最先運用在 NVIDIA Volta™ 架構上,不隻大幅加速人工智能,也将訓練時間從數周降至數小時,同時顯著提升推論速度。NVIDIA Ampere 架構以這些創新技術爲基礎,采用全新精度标準 Tensor Float 32 (TF32) 與 64 位浮點 (FP64),以加速并簡化人工智能應用,同時将 Tensor 核心效能拓展至高效能運算。
TF32 與 FP32 運作方式相同,無需更改任何程序代碼即可将人工智能速度提升至最高 20 倍。透過 NVIDIA 自動混合精度,研究人員隻要多加幾行程序代碼,就可以利用自動混合精度和 FP16 将效能提升 2 倍。而 NVIDIA Ampere 架構 Tensor 核心 GPU 中的 Tensor 核心透過支持 bfloat16、INT8 與 INT4,能爲人工智能訓練和推論創造極緻多元的加速器。A100 和 A30 GPU 不隻将強大的 Tensor 核心導入高效能運算,也支持完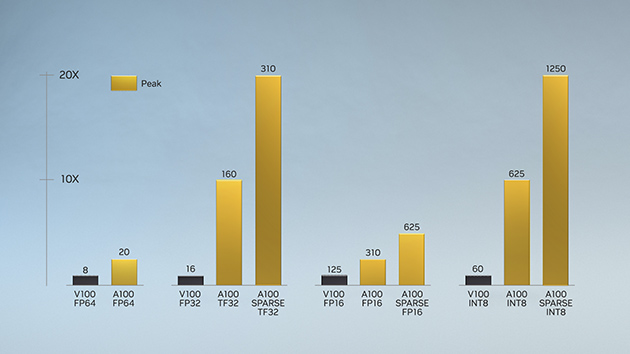
多實例 GPU (MIG)
每個人工智能與高效能運算應用都能受益于加速,但并非所有應用都需要使用 GPU 的完整效能。多實例 GPU (MIG) 是 A100 和 A30 GPU 支持的功能,可讓工作負載共享 GPU。MIG 讓每個 GPU 能分隔成多個 GPU 實例,各自在硬件中完全獨立且受保護,且具備個别的高帶寬内存、快取和運算核心。現在不論大小,開發人員可爲所有應用提供突破性加速,并獲得服務質量保障。IT 管理人員可爲最佳利用率提供規模适中的 GPU 加速,并将橫跨實體與虛拟環境的訪問權限擴展給每個使用者和應用。

第三代 NVLink
在跨多個 GPU 上擴充應用程序需要極快的數據移動速度NVIDIA Ampere 架構中的第三代 NVIDIA® NVLink® 可将 GPU 到 GPU 的直接帶寬翻倍,達到每秒 600 GB (GB/秒),比第四代 PCIe 速度快近 10 倍。搭配最新一代 NVIDIA NVSwitch™ 使用時,服務器中的所有 GPU 都能透過 NVLink 全速相互交流,執行極高速的數據傳輸。
NVIDIA DGX™A100 和其他頂尖計算機制造商的服務器充分運用 NVLink 和 NVSwitch 技術,透過 NVIDIA HGX™ A100 爲高效能運算和人工智能工作負載打造的基闆,提供更爲優良的擴展性。

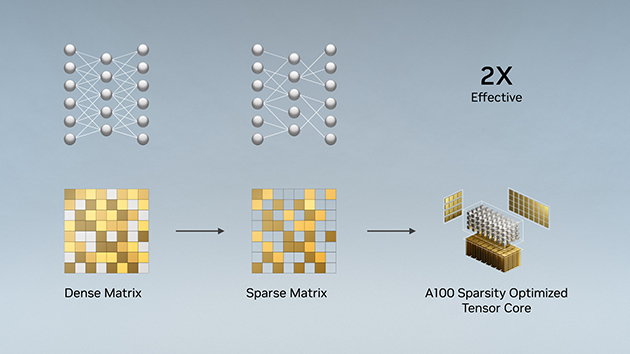
結構化稀疏
現代人工智能網絡相當龐大且越來越大,有數百萬、甚至數十億個參數。精準預測與推論不需要用到所有參數,而有些參數可以轉換爲零,以确保模型變「稀疏」的同時不會犧牲準确性。Tensor 核心最高可以将稀疏模型的效能提高 2 倍。将模型稀疏化對于人工智能推論有益,同時也能改善模型訓練效能。
第二代 RT 核心
NVIDIA A40 中,NVIDIA Ampere 架構的第二代 RT 核心可大幅提升電影作品的拟真渲染、建築設計評估,以及産品設計的虛拟原型制作等工作負載的速度。RT 核心還能加速光線追蹤于動态模糊的渲染效果,以更快的速度獲得更高的視覺準确度,還能在執行着色或噪聲消除功能的同時,執行光線追蹤。

更聰明、快速的内存
A100 爲數據中心提供大量運算效能。爲充分運用運算引擎,A100 具備領先同級産品的每秒 2 TB (TB/秒) 内存帶寬,比前一代産品高出 2 倍多。此外,A100 的芯片内存也顯著增加,具備 40 MB 的 2 級快取,爲上一代産品的 7 倍,可将運算效能最大化。

爲規模化部署而優化
NVIDIA GPU 和 NVIDIA 融合加速器産品專爲大規模部署而打造,爲雲、數據中心和邊緣融合網絡、提升安全和降低功耗。
爲各種服務器優化性能
NVIDIA A2 GPU提供産品組合中最小的占用空間,針對空間和散熱要求受限的入門級服務器中的推理工作負載和部署進行了優化,例如 5G 邊緣和工業環境。A2 提供了在低功耗範圍内運行的半高外形,将熱設計功耗 (TDP) 從 60 瓦降到 40 瓦,使其成爲衆多服務器的理想選擇。

統一計算和網絡加速
在 NVIDIA 融合加速器中,NVIDIA Ampere 架構和 NVIDIA BlueField®-2 數據處理器 (DPU) 協力爲邊緣計算、電信和網絡安全領域的 AI 工作負載帶來非凡的性能、更高的安全性和更穩定的網絡。而 BlueField-2 則将 NVIDIA ConnectX®-6 Dx 的高性能與可編程的 ARM® 核心以及硬件卸載功能相結合,用于軟件定義存儲、網絡建設、安全和管理等方面。NVIDIA 融合加速器能夠爲網絡密集型且需要 GPU 加速的工作負載提供更高水平的數據中心效率和安全性。

密度優化的設計
NVIDIA A16 GPU 采用四 GPU 主闆設計,專爲用戶密度優化,并結合了 NVIDIA 虛拟 PC (vPC) 軟件,讓用戶無論身在何處都可以使用繪圖運算豐富的虛拟 PC。與僅使用 CPU 的 VDI 相比,NVIDIA A16 可提供更高的幀速率和較低的終端用戶延遲,因此應用程序反應能更靈敏,并帶來與原生 PC 無異的使用者體驗。

安全部署
安全部署對企業業務運營至關重要。NVIDIA Ampere 架構通過可信代碼身份驗證和強化的回滾機制來防禦惡意軟件攻擊,從而支持安全啓動,并防止操作損失和确保工作負載加速。

專業功能
NVIDIA A10 将執行計算機輔助設計 (CAD) 和設計應用程序,且繪圖豐富的虛拟化工作站所需的效能與功能,與加速 VDI 和運算所需的彈性結合在一起。
遠程協作 企業級 3D 可視化 加速應用程序 交互式渲染技術
遠程協作
運用專爲虛拟協作打造的開放式平台 NVIDIA OmniverseTM, 開創協作的新紀元,将您的虛拟化工作站提升至全新境界。使用者和團隊連接設計工具、資源和項目,在虛拟世界中進行協作式叠代,使得複雜的創作、設計和工程視覺工作流程也随之改變。
A10 技術規格和功能
| FP32 | 31.2 兆次浮點運算 |
| TF32 Tensor 核心 | 62.5 兆次浮點運算 | 125 兆次浮點運算* |
| BFLOAT16 Tensor 核心 | 125 兆次浮點運算 | 250 兆次浮點運算* |
| FP16 Tensor 核心 | 125 兆次浮點運算 | 250 兆次浮點運算* |
| INT8 Tensor 核心 | 250 兆次浮點運算 | 500 兆次浮點運算* |
| INT4 Tensor 核心 | 500 兆次浮點運算 | 1,000 兆次浮點運算* |
| RT 核心 | 72 個 RT 核心 |
| 編碼/譯碼 | 1 個編碼器 2 個譯碼器 (+AV1 解碼) |
| GPU 内存 | 24GB GDDR6 |
| GPU 内存帶寬 | 每秒 600 GB |
| 互連技術 | 第四代 PCIe 64GB/秒 |
| 尺寸規格 | 單插槽、全高全長尺寸 (FHFL) |
| 最大散熱設計功耗 (TDP) | 150W |
| 虛拟化 GPU 軟件支持 | NVIDIA 虛拟 PC、NVIDIA 虛拟應用程序、NVIDIA RTX 虛拟化工作站、NVIDIA 虛拟化運算服務器, NVIDIA AI Enterprise |